Caching
All Content APIs are served via our globally distributed edge cache. Whenever a query is sent to the content API, its response is cached in multiple POP (data centers) around the globe.
 Hygraph CDN Map
Hygraph CDN Map
Hygraph handles all cache management for you! For faster queries, use GET requests, so browsers can leverage advanced caching abilities available in the headers.
Hygraph comes with two different content API endpoints, served by 2 different CDN providers. To understand which endpoint you should use, look at the following table.
| Endpoint name | Endpoint | Consistency | Access |
|---|---|---|---|
| Regular read & write endpoint | https://${region}.hygraph.com/v2/${projectId}/${environment} | Eventual (Read-after-write within POP) | Read & Write |
| High performance endpoint | https://${region}.cdn.hygraph.com/v2/${projectId}/${environment} | Eventual | Read & Write |
CDN = Content-Delivery-Network
You can see the endpoints in your project settings (Settings->API Access->Endpoints).
#Regular read & write endpoint
The Regular read & write endpoint allows for reads and writes. All your requests are cached, and any mutation will invalidate the cache for your project.
Even though this endpoint is eventually consistent, within a single region you will get read-after-write consistency.
This endpoint can take up to 30s to update all caching nodes worldwide.
This endpoint is ideal for delivering content around the globe with one endpoint, but it only has basic caching logic.
#High performance endpoint
We use a state-of-the-art caching approach, and we have developed a high-performance edge service on the Fastly Compute Edge platform. The service is deployed close to your users around the world.
You will benefit from continual improvements on the cache invalidation logic without any code changes on your part.
This endpoint is ideal for delivering content around the globe with low latency and high read-throughput.
This endpoint has model + stage based invalidation. This means that instead of invalidating the complete cache for content and schema changes, we only invalidate the models that were changed based on the mutations used. The rest will stay cached and, therefore, fast. Click here to learn more.
In some cases, entry-based cache invalidation is possible. Click here to learn more
#Consistency
To understand both endpoints better, you should have a basic knowledge of cache consistency modes. You can be sure that any changes have persisted at Hygraph if your response was successful.
#Eventual consistency
Some changes are not visible immediately after the update. For example, if you create, delete or update content the update is distributed around the globe with a short delay. Theoretically, if you read content right after a mutation, you may receive stale content.
#Read-after-write consistency
In contrast, read-after-write consistency guarantees that a subsequent read after an update, delete, or create can see those changes immediately. This is only valid for operations hitting the same POP (point-of-presence).
#Model + stage based invalidation
Model + stage based invalidation, which is only available for our High performance endpoint, allows invalidating only the models that were changed based on the mutations used for content and schema changes, rather than invalidate the complete cache.
Regarding queries that fetch related content that needs to be invalidated: We analyze query responses and invalidate only the cached queries that contain the changed model.
For example:
Considering invalidation after a schema change, if a user were to update the Author model shown in the example above, this cached query would be invalidated, as it also returned the Author model.
For content changes, we also take the stage into account, meaning that updating an Author entry, and not publishing it, would invalidate all cached queries that returned the DRAFT stage and the Author model. Queries that returned the PUBLISHED stage will remain cached.
#Smart cache invalidation
Our System understands if mutations are flowing through the cache and invalidates the affected resources with an eventual consistency guarantee.
#Entry-based cache invalidation
In some cases, cache invalidation can be done on an entry basis.
- Caching of content of different stages remains independent.
- Mutation of content in the
DRAFTstage won't invalidate content in thePUBLISHEDstage.
There are three scenarios where entry-level tagging is applied and invalidation becomes more granular, targeting only responses embedding specific entries:
- Query of a single entry by
id - Single reference fields
- Query of multiple models with a
whereargument involving only unique fields (like a slug)
We'll use the following example situation to explain the three possible cases:
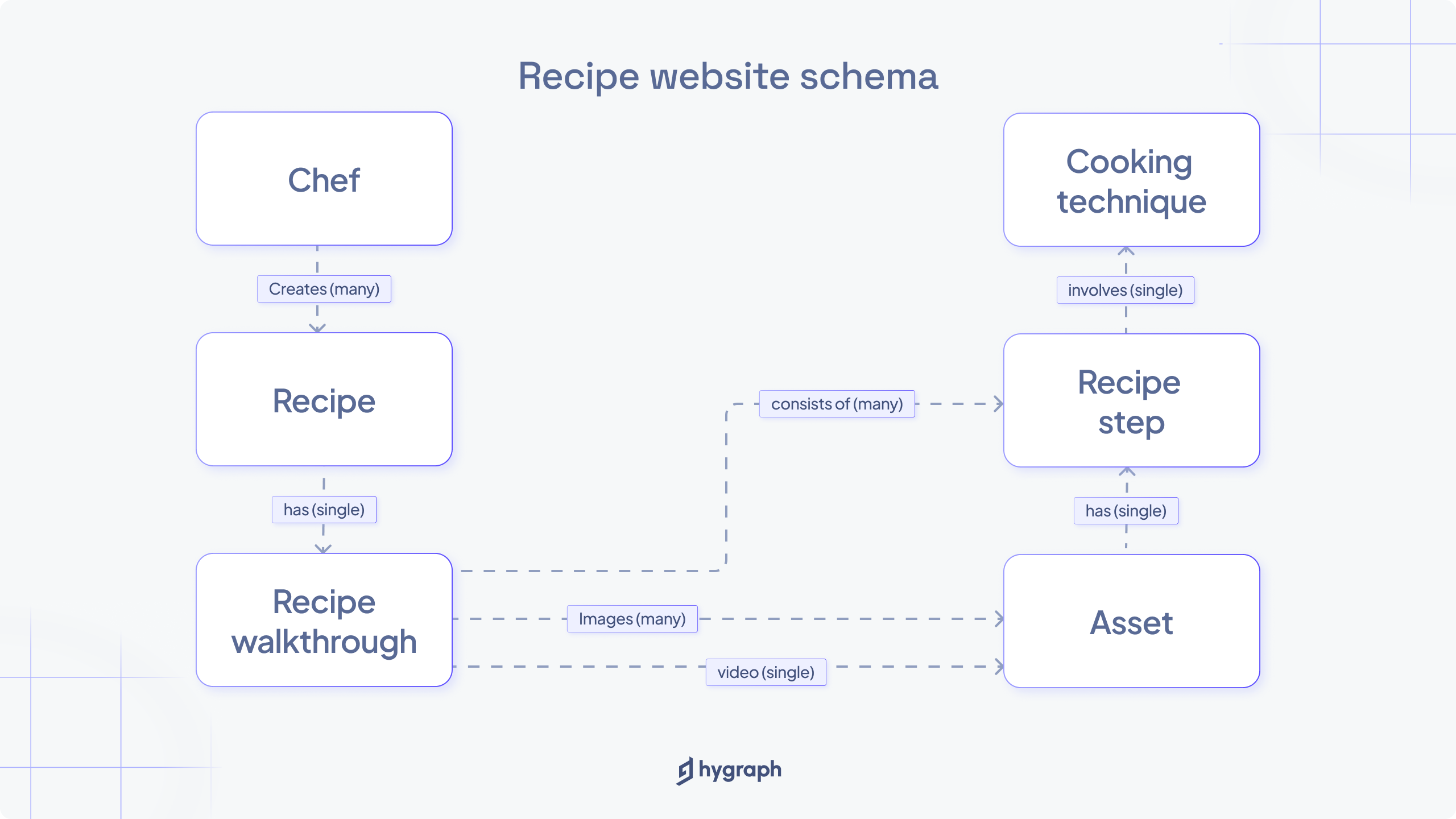 entry-based-caching
entry-based-caching
Let's consider the schema above. It represents a mock of a recipe website presenting image descriptions and preparation steps of the various dishes. Each recipe is also linked with a chef who created it.
The GraphQL snippets in the following examples use the flag [EBC] to identify invalidation scenarios that work at entry level.
#Query of a single entry by id
Following our recipe website example situation, in this scenario we query a single recipe (entry). When that recipe is found, the cached response for the query is only invalidated if there are mutations sent that affect this specific entry.
The cached response will remain valid after mutations targeting other recipes, or any other model.
# Invalidated on# - changes to Recipe 'cltx865t89nu607uj4tvaact5' [EBC]query {recipe(where: {id: "cltx865t89nu607uj4tvaact5"}){idtitledescription}}
#Single reference fields
In this scenario and following our example situation, the query targets multiple recipes along with their associated chefs.
Here, the cache mechanism becomes a little more complex as it has to deal with multiple relationships:
# Invalidated on:# - changes or creation of any Recipe# - changes of specific Chef related to the returned recipes [EBC]query {recipes(first: 5) {chef { #single reference fieldidnamebio}}}
Changing any of the recipes or adding new recipes, will invalidate the cache associated with this query.
This is because the query fetches the first five recipes, and any changes or additions could potentially alter this result.
Additionally, any changes to the specific chefs who are directly associated with the returned recipes will also invalidate the cache. Other chefs' information will not affect the response and so it does not invalidate the cache.
The EBC behavior from the previous snippet does not apply if chef parameters are part of the query where argument:
# Invalidated on:# - changes or creation of any Recipe# - changes or creation of any Chefquery {recipes(where: {chef: {birthdate_gt: "1990-04-05T00:00:00Z"}}) {chef {idnamebio}}}
Since the chef's birthdate is now a determining factor in the query results, any changes or additions to the chefs - regardless of their association with the returned recipes - can potentially alter the result of this query. For example, the birthday of another chef is updated and becomes included by the filter.
Because of this, even modifying or adding chefs not directly associated with the returned recipes invalidates the cache.
Nested references
Entry-based cache invalidation also applies when the reference fields are nested deeply in the query tree, even if they are children of multi reference fields.
# Invalidated on:# - changes or creation of any Chef# - changes or creation of any Recipe# - changes of specific RecipeWalkthrough related to# the returned recipes [EBC]# - changes of specific Asset(video) related to# the returned RecipeWalkthrough [EBC]query {chefs { # multi model querynamerecipes { # multi reference fieldrecipeWalkthrough { # single reference fieldvideo { # single reference fieldfileNameurl}}}}}
In this scenario, where the query involves multiple models and their relationships, the cache invalidation becomes a bit complex.
Following our recipe website schema example: Any changes or additions to the chefs, recipes, or recipe walkthroughs, will invalidate the cache associated with this query. Additionally, any changes or additions to the specific assets (videos) related to the returned recipe walkthroughs will invalidate the cache as well.
Modifying or adding assets not directly associated with the returned recipe walkthroughs does not affect the cache, so it will remain valid.
#Multi-model query with unique fields only
This will only work for non-localized unique fields.
In the following example, we are querying for a single recipe based on a unique field - the slug:
# Invalidated on:# - changes of specific `Recipe` with slug "classic-spaghetti-carbonara"query {recipe(where:{ slug: "classic-spaghetti-carbonara"}) {idslugtitledescriptioncreatedAt}}
The cache will be invalidated only if there are changes to the specific recipe with the slug "classic-spaghetti-carbonara".
Any changes to other recipes will not affect the cache associated with this query.
In this other example, the query fetches chefs and the recipes associated with each chef based on a unique field - the slug:
# Invalidated on:# - changes or creation of any Chef# - changes of specific `Recipe` with slug "classic-spaghetti-carbonara"query {chefs {idnamerecipes(where: {slug: "classic-spaghetti-carbonara"}) {idtitledescription}}}
The cache will be invalidated if there are changes to the specific recipe with the slug "classic-spaghetti-carbonara" or any changes or additions to the chefs.
Any changes to other recipes not having the slug "classic-spaghetti-carbonara" will not affect the cache associated with this query.
#stale-if-error
In case of an outage of our APIs - this includes remote field origin errors as well- we will fall back for at least 24h to the latest cached content on our edge servers. This adds an additional reliability layer.
This is only available on the High performance endpoint.
The default Stale-if-error for all shared clusters is 86400s (1 day).
You can use a header for the High performance endpoint that lets you set stale-if-error on a per query basis.
{"hyg-stale-if-error": "21600"}
The values are in seconds.
#stale-while-revalidate
With the High performance endpoint you will get cached responses directly, while we update the content in the background. This means your content is always served on the edge, with low latency for your users.
Staleness refers to how long we deliver stale data while we revalidate the cache in the background if the cache was invalidated.
This is only available on the High performance endpoint.
The default stale-while-revalidate for our shared clusters is 0.
You can use a header for the High performance endpoint that lets you set stale-while-revalidate on a per query basis.
{"hyg-stale-while-revalidate": "27"}
The values are in seconds.
#Remote fields
GraphQL queries that contain remote fields are cached differently. By default, a response is marked as cacheable when all remote field responses are cacheable according to rfc7234. You can control the TTL (Time-to-Live) cache by returning the Cache-Control response header.
By default, we will set a TTL of 900s, you can set a minimum TTL of 60s. While it is also possible to respond with a no-store cache directive to disable the cache, this is not recommended, as it marks the entire response as not cacheable and will increase the load on your origin.